Unleash the DevOps!

By
5 min read

DevOps tools have come a long way. From virtual machines in dev and QA environments to those in production, and now Docker. The more we are charmed by the idea of hardware as a code, the crazier the things we are trying to do with it. Take the “immutable server” pattern as an example. In 2000, how crazy was the idea of throwing away a perfectly good server because the configuration changed?! Today, we understand that state changes are not maintainable; they are the root of all evil, and (thanks to hardware as code) throwing the server away instead of changing it is the right way to go. But how about an immutable data center? I mean, why not? It’s the next logical step, isn’t it? Instead of re-configuring whatever is in charge of baking new servers every time configuration has changed, (I mean the CI server, the artifact repository and the provisioning server), why not to throw it away and spin up a new one?
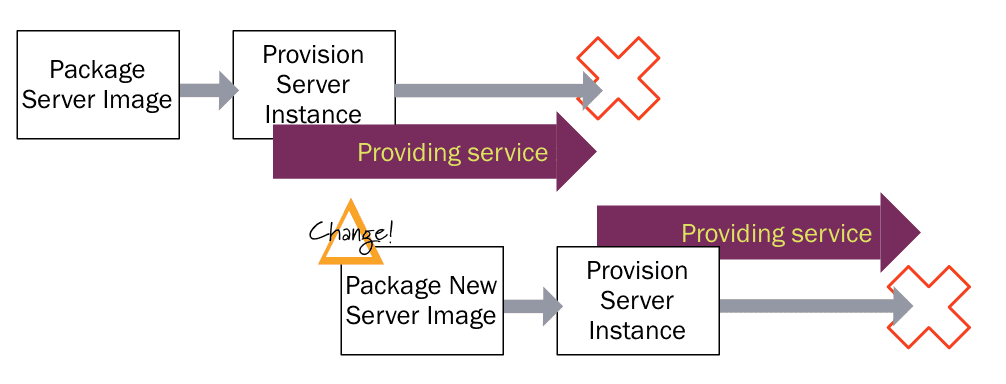
(Source: https://martinfowler.com/bliki/ImmutableServer.html)
Now, starting with Artifactory 5, you can! It can be completely automated by robots; not only basic operation (we always knew that 95% of the interaction with Artifactory is done by robots), but also provisioning, configuration and decommissioning. A cluster of Artifactory servers can be spun up (including license pool management), configured with the right repositories, configuration, and permissions, elastically scaled, and then killed, when this data center is destroyed instead of being changed (and the licenses will return to the pool to be reused). So, here’s what it takes to fully configure Artifactory with a valid license, custom Base URL, reverse proxy for Docker support, and fully configured set of repositories for Docker, npm, Maven and RPM.
And how do you put this beauty to use? By spinning up an Artifactory server, complete with database, nginx and the whole shebang using Docker Compose (or start Artifactory in any other way) with this yaml file in your $ARTIFACTORY_HOME/etc folder. Cool? Uber cool!
Talking about permissions and security, as Artifactory is managed by robots instead of people more and more, user management no longer makes sense. Robots don’t have email addresses and can’t login to their profile to change their passwords. Usernames and passwords are the past, access tokens are the future. They are flexible enough to contain all the permission information, providing the right access to the right resource; they are expirable by usage and/or by time, and they are created, managed and destroyed for robots by other robots. How cool is that (and a bit freaky, too)!
Back to DevOps tools and the proliferation of hardware as code, two of the main players in that market are Chef and Puppet. Their cookbooks and modules respectively, are the code that creates the servers and complete datacenters that we spoke  about. They are part of our pipeline for delivering those datacenters with servers in them, and as part of the pipelines, they have to be associated with the other parts of the pipeline. For example, which server is created by a specific cookbook. Changes in cookbooks create changes in servers, but other changes are usually added in as well. How do you correlate between a new version of a jar file, which comes from the Java build part of the pipeline with a new version of the JDK this jar file is compatible with, that comes from the cookbook?
about. They are part of our pipeline for delivering those datacenters with servers in them, and as part of the pipelines, they have to be associated with the other parts of the pipeline. For example, which server is created by a specific cookbook. Changes in cookbooks create changes in servers, but other changes are usually added in as well. How do you correlate between a new version of a jar file, which comes from the Java build part of the pipeline with a new version of the JDK this jar file is compatible with, that comes from the cookbook?
Bringing all those parts of the pipeline to a single tool provides the ability to annotate them with referenceable metadata. With Artifactory 5.1 and its support for Chef cookbooks and Puppet modules, you can mark a module that sets up a server with that new version of JDK as being compatible with the java build that produced that jar file that requires this JDK version.
And then comes the magic – you can search for them. Using Artifactory Query Language you can now spin off a datacenter, that has the correctly configured CI server (the slav es have the correct JVM version), the correctly configured artifact repository (all the repositories are preconfigured, and the right access tokens are generated) and the correctly configured servers
es have the correct JVM version), the correctly configured artifact repository (all the repositories are preconfigured, and the right access tokens are generated) and the correctly configured servers
for each stage of the pipeline, again, with the correctly generated servers with the right JVM version, all that just by using the right Puppet modules or Chef cookbooks. How do you know which modules are right? By querying Artifactory to give you the right files (modules, cookbooks, docker images and application files) based on the target environment.
Is that DevOps on steroids, or what?!


